
In this section, we describe how we selected funds to include in Rethink Priorities’ Cross-Cause Fund.
Methodology
Learn how we select funds for re-granting, estimate cost-effectiveness across cause areas, and model our allocation recommendations.
How it works
Fund selection
Funds and areas under consideration
- Democracy protection (non-partisan): We are conducting research to determine whether we can responsibly include this area while remaining compliant with our legal obligations.
- Climate change: We are assessing whether existing climate-focused funds meet our quality and data requirements for inclusion.
- Effective giving (meta): We may investigate funds focused on movement-building, cause-prioritization research, and similar activities that aim to increase the overall effectiveness of philanthropic giving.
Some funds that we intend to vet for inclusion in the future: Ambitious Impact funding circles (Mental Health, Meta Charity, Seed Network, Global Health, Strategic Animals), Giving Green, The Life You Can Save, AI Safety Tactical Opportunities Fund, Astralis Foundation, Survival and Flourishing Fund, Animal Charity Evaluators' Recommended Charity Fund (ACE), Senterra Funders, Macroscopic Ventures, EA Infrastructure Fund, Coefficient Giving Funds (e.g., Global Growth Fund, Abundance & Growth Fund).
How did we select these funds?
Broad cause coverage
We aimed to include at least one fund in each of the major cause areas we assess: global health and development, animal welfare, and global catastrophic risks.
Fund quality
We included only funds we were confident would lead to high-impact grants. We did not include areas where we have insufficient experience to vet the fund quality.
Data availability
We could only include funds for which we could obtain relevant cost-effectiveness data or for which there was sufficient publicly available data to model cost-effectiveness.
Decision relevance
The initial fund list was shaped by the giving decisions we anticipated to be most relevant for early users. This pragmatic consideration will carry less weight in future versions.
Legal and organizational restrictions
As a 501(c)(3) public charity, Rethink Priorities is prohibited from supporting or opposing candidates or parties for public office. We therefore exclude political giving entirely from the Cross-Cause Fund.
Cross-cause prioritization model
This section describes the model used by RP Cross-Cause Fund and RP Donor Compass. The model delivers allocation recommendations to users based on a range of inputs, including the fund-by-fund cost-effectiveness estimates and several other variables described below.
Model inputs
Worldview credences
The model proposes multiple worldviews (coherent bundles of ethical commitments and empirical beliefs). Each worldview is assigned a credence reflecting its weight in the final aggregation.
Moral weights
Each worldview specifies how to compare welfare improvements across different effect types. The base unit is one human life-year (weight = 1.0). Other effects, like human YLDs (Years Lived with Disability) averted, income doublings, and animal DALYs (Disability-Adjusted Life Years for mammals, chickens, fish, shrimp, other invertebrates), are weighted relative to it.
Discount factors across time periods
Each worldview assigns a discount factor (0-1) to six time periods: 0-5, 6-10, 11-20, 21-100, 101-500, and 501+ years. These factors reflect how much weight to give to impacts in each period compared to immediate effects. A value of 1.0 weights that period equally to immediate impacts; 0.0 excludes it entirely. A value of 0.2, for example, reflects the belief that the given time period is so uncertain that one would assign an 80% chance that their actions would not affect it.
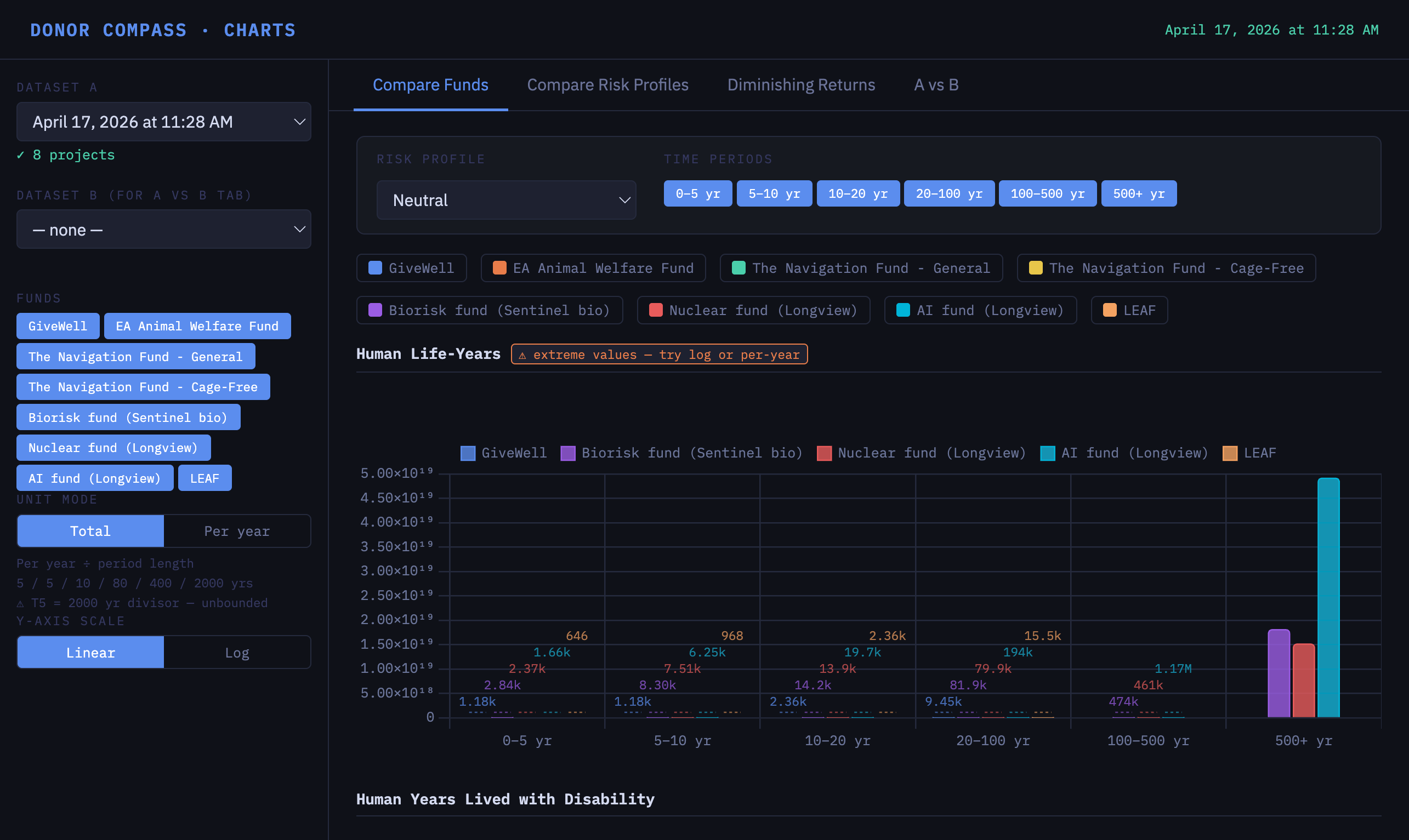
Risk profiles
Each fund's impact is modeled as a distribution of cost-effectiveness, achievable outcomes per $10 million. Each worldview is assigned a risk profile, which later determines how the distribution is collapsed into a score. The available profiles range from risk-neutral expected value calculations to various risk-averse options.
Discount factor for non-AI risk interventions
For worldviews that assign weight X to the possibility of a near-term AI catastrophe, a discount is applied to the scores of funds that do not directly target AI risk reduction, reflecting an X% chance that AI does something extreme that erases the impact of non-AI interventions.
Fund-by-fund cost-effectiveness estimates
As described in the section below.
Steps we follow to output allocation recommendations
Step 1: Define worldviews
The user (Rethink Priorities, or the donor themself) specifies one or more worldviews, each defined by moral weights, time-period discount factors, a risk profile, an AI risk discount factor, and a credence. These worldviews make explicit the user's ethical and empirical assumptions underlying the allocation.
Step 2: Score each fund under each worldview
For each charitable fund, we hold modeled estimates of its cost-effectiveness. This is structured as expected impact per amount spent, broken down by:
- effect type (e.g., human life-years affected)
- time period (e.g., 6-10 years)
- risk profile (e.g., neutral)
Each worldview applies its:
- assigned moral weights
- time-period discount factors
- risk profile selection
- AI risk discount factor
to produce a single, collapsed score for each fund under that worldview (more on this below).
Step 3: Aggregate fund scores across worldviews
There are various ways to combine scores from different worldviews into a final allocation. We call these methods aggregation methods. Per-worldview scores are combined into a single portfolio allocation using one of nine aggregation methods (e.g., Nash bargaining). Because no single method is universally accepted as correct, different methods can be applied to successive tranches of a donation.
Step 4: Output a portfolio
The model processes the total donation in $10M increments, distributing funds at each step according to the chosen aggregation method and accounting for diminishing returns as follows: At each allocation stage, each fund's score is adjusted by a diminishing-returns factor included in our fund-level data. The more a fund has already received, the lower this factor is, reflecting that the most impactful opportunities within a fund get funded first. The output is a recommended allocation across funds expressed as a percentage of the total budget.
Here is a walkthrough with examples to illustrate the steps described above.
Fund-by-fund cost-effectiveness estimation
This section describes how Rethink Priorities estimates the following for each fund:
- How cost-effective is the fund at the margin today?
-
How quickly does cost-effectiveness decline as the fund
receives more money?
To estimate the cost-effectiveness and diminishing returns curve of each fund, we followed these general steps:
- Create a cost-effectiveness framework for each fund and identify key data needs.
- Solicit data from each fund; where unavailable, create in-house estimates.
- Simulate marginal cost-effectiveness across each impact dimension.
- Collapse the simulated cost-effectiveness data into a single number based on different risk preferences.
- Construct diminishing-returns curves for each fund. This curve is used in the Donor Compass model to adjust the impact of each additional $10M allocated to a fund, given its prior allocations.
Impact metrics by cause area:
-
For global health and development funds:
- Years of life saved from premature death
- Years of disability and illness averted
- Income gains to program recipients (standardized as income doublings that last a year)
-
For animal welfare funds:
- Years of suffering avoided for animals from the following species: chickens, fish, shrimp, non-shrimp invertebrates (e.g., insects)
-
For the global catastrophic risk funds:
- Expected years of life saved from mitigating catastrophes
We thus describe each of these three modeling frameworks at the following links:
Data Viewer
Open our Data Viewer to inspect the fund-by-fund cost-effectiveness data that feeds into Donor Compass recommendations and Cross-Cause Fund allocations. To help you understand the data, we created this brief overview explaining how to read it.
Model limitations
Uncertain inputs
Several parameters the model relies on are not well established, and reasonable changes to them can meaningfully shift the final allocation. We've consulted experts in our network to arrive at best guesses, but readers should treat these as informed estimates rather than settled facts. We don't think the effective altruism community currently has good answers to many of these questions, and we plan to involve more experts in future iterations. Several examples are worth flagging:
- Attributing extinction risk across causes. How to split total extinction risk among AI, biological, and nuclear risks is genuinely uncertain, and small changes in these shares can shift significant portions of the allocation. Similarly, how much these extinction risks can be reduced by specific interventions is an uncertain assumption in our modeling work.
- Far future and extinction-risk impact. It is very difficult to confidently assess the long-run impact of a project. We mitigate this by assigning probability distributions to all inputs, by considering different scenarios with different levels of conservatism (for example, capping the time horizon at roughly 100 years in some worldviews), and applying different risk-weighting functions (some are risk-neutral, others penalize outcomes that are very unlikely to occur). In the future, we may expand upon the methods we're using to treat future uncertainty.
- How much credence to give to each moral theory. How much weight to assign to different moral theories also affects the result, and there is no clear-cut answer to how to set these credences.
- Cost-effectiveness estimates at the fund level. We estimate each fund's cost-effectiveness by combining estimates for the interventions we expect it to support, using a mix of historical and forward-looking data. The underlying data varies in quality: not all funds have detailed cost-effectiveness estimates available, and those that do vary in how transparent or self-critical their assumptions are. We have tried to level the playing field through adjustments so that conservative, self-critical funds are not penalized for their conservatism, but this requires subjective judgment. The model also does not capture our subjective confidence in particular grantmakers, and funds may reasonably change direction over time, so what each fund actually supports going forward may differ from the mix we have assumed. We hope to keep improving this as capacity allows.
In addition to involving more experts, we are working on a more advanced sensitivity analysis to assess how changes in the distributions of our inputs affect our ultimate recommendations.
Limited set of funds and cause areas included
We've included a small number of funds, and several cause areas are not represented at all. Most notably, climate and democracy preservation are not currently covered, and neither are "meta" causes aimed at improving giving decisions or expanding the number of people working on priority causes. We hope to include democracy and potentially climate work later this year. Rethink Priorities is a 501(c)(3) organization and is legally prohibited from supporting or opposing political candidates or parties, so giving to political candidates is also outside the model. Beyond these specific exclusions, we did not include many strong funds due to capacity constraints. Absence from this list should not be read as a judgment that a fund is less cost-effective than those we've covered.
The ability to capture interaction dynamics
Interaction effects between grantmakers
In certain cases, what one funder does will impact what another funder does. Sometimes they may pull a new funder into the space or crowd out a different actor (this is sometimes known as "funging"). If what we care about is overall impact, then we should consider these effects. However, these effects are difficult to model due to a lack of data on what someone would do in a counterfactual scenario, and they can differ substantially within and between areas.
For our purposes, we have selected funds that are in touch with other actors in their respective spaces, which should limit the impact of this concern. However, actors not in those spaces, particularly outside effective giving circles, may be causally affected by their actions in ways that are difficult to account for.
This may be a smaller issue in smaller fields, where it's less likely that other funders will step in. And a bigger issue in fields with more money is that a number of actors can make any given grant and may be interested in doing so.
Interaction effects between grant recipients
In some areas, grant recipients largely operate independently of one another, but in others, particularly in the policy space, a single bad intervention or action could harm the prospects or outcomes of related interventions. In our model, this type of concern may be most salient for AI grantmakers (where multiple actors are trying to influence policy in the same countries and locations) and less relevant for GHD (where interventions operate under different theories of change in very different countries). For animal interventions, certain actions may be more tightly correlated, like corporate campaigns where success may depend on keeping the public on your side, and a single rogue actor could harm the chance of success for all.
Using judgment calls, reasonable people could disagree with
A number of the methodological decisions behind the model do not have a clear best answer, and choosing a different one would change the recommendation. For example, one of the risk profiles we use is skeptical of benefits that are very unlikely to occur. We currently implement this by fully counting all outcomes except the top 2.5% and discounting those in the top 2.5%. The exact threshold is a judgment call, not a settled methodological standard, and a different threshold would have produced different results. Similarly, all interventions are currently modeled as having diminishing overall effectiveness as funding scales, with no distinction between an intervention whose probability of success falls and one that becomes more likely to backfire or have no effect. Different moral theories and risk attitudes would treat those situations differently. We are running sensitivity analyses to better understand how much these choices matter, and we hope to refine our treatment in future iterations.
No settled answer for how to combine recommendations across moral views
Aggregating across moral views is a young and unsettled area, and the choice of method does influence results. We have extensively reviewed the available literature on this topic and commissioned a report from Harry Lloyd, a philosopher specializing in moral uncertainty. Our model implements several aggregation methods and combines them using the weighted factor model described in this document.
Representing non-utilitarian moral theories in simplified form
Our model uses simplified versions of non-utilitarian theories, and does not yet include virtue ethics or the capabilities approach. We hope to add both in future iterations. One simplification is worth flagging.
To produce a recommendation, the model has to combine impacts across many people or animals (for example, weighing small harms to many against a large harm to one) and assign each option a single number so options can be compared. This naturally fits the reasoning of consequentialist theories. But non-consequentialist theories, such as deontology, do not fit this structure. The non-consequentialist theories represented in our model are better thought of as proxies for the recommendations these theories would make, rather than as reflecting the structure of their reasoning. We plan to keep iterating on our treatment of these theories in future versions.
More broadly, in its current form, our methodology rests on the assumption that the goal of giving is doing as much good as possible, where 'good' is defined by the donor's own worldview weights across welfare, risk reduction, and moral views. It is aimed at readers who broadly accept this quantitative lens.
More on our methodology
Why explicit modeling is so important
Learn about why explicit quantitative models, despite their limitations, remain more reliable than intuition or heuristics for high-stakes resource allocation decisions, and why the alternative of informal reasoning often hides the same problems while adding new ones.
Dive deeper into this topic with In Defense of Modeling.
Aggregation methods
Learn about how to combine views across multiple moral theories when making donation decisions, why no single aggregation method should receive more than 50% of your credence, and why a weighted average across approaches may be the most defensible strategy.